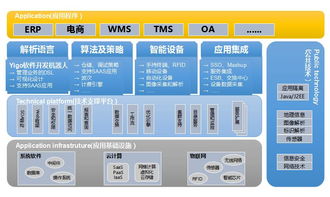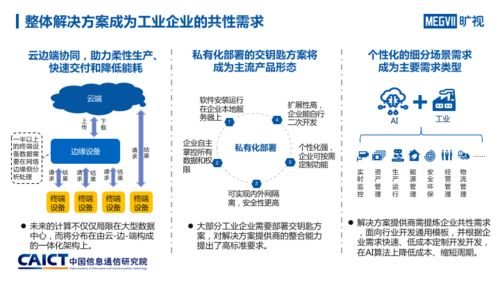
隨著人工智能(AI)技術的快速發展,訓練大規模模型已成為行業常態。單個計算節點的資源限制常導致訓練時間過長,甚至無法完成任務。分布式訓練技術應運而生,通過將計算任務分解到多個節點并行處理,有效提升了訓練效率和模型性能。
分布式訓練的核心方法包括數據并行和模型并行。數據并行將訓練數據分割到不同節點,每個節點持有完整的模型副本,通過梯度同步(如使用All-Reduce算法)實現參數更新;模型并行則將模型結構拆分到不同節點,適用于超大規模模型(如GPT-4),解決單個設備內存不足的問題。混合并行策略結合了兩者優勢,例如在Megatron-LM等框架中廣泛應用。關鍵技術如參數服務器架構和All-Reduce通信優化(如Ring-AllReduce)進一步降低了通信開銷。
在人工智能應用軟件開發中,分布式訓練技術顯著加速了產品迭代。以智能語音助手為例,開發團隊可利用Horovod或PyTorch Distributed框架,在GPU集群上并行訓練聲學模型,將數周的訓練時間縮短至幾天。分布式訓練支持更大規模數據的處理,提升了模型在復雜場景下的準確性,如自動駕駛系統中的視覺識別模塊。開發者需注意數據分布一致性、節點故障恢復等挑戰,并借助Kubernetes等工具實現彈性資源調度。
隨著異構計算和聯邦學習等技術的融合,分布式訓練將進一步推動AI應用軟件的創新,幫助企業在醫療、金融等領域實現高效智能化轉型。